A Developer’s Primer on CorDapp Upgrades
October 06, 2020

You have done the hard work. The CorDapp is out there, chugging along on the node in production, the keyboard is still sticky from the champagne popped on the go-live day. Life couldn’t get any better.
But the Product Owner has a mile-long backlog, with bug fixes and new features. Before you know it, there’s a new version of the CorDapp taking shape for the next release. An upgrade release.
The combination of an immutable ledger platform and the idea of an “upgrade” almost inevitably makes one’s head itch so in this blog, we will take a closer look at what we can upgrade and how we do it.
Setting ourselves up for success
You really should be using signature constraints
That’s because they are the most convenient way to roll out new code and have the new code pick up the ledger where the previous version of the code left it. Everything in this blog post should still apply, even if you use the whitelist constraint, but you will find the “go and redeploy your CorDapp” step significantly easier if you use signature constraints. More about contract constraints here.
Try to use latest Corda version
Corda keeps improving in all aspects and the evolution of CorDapps is no exception. Here’s an example: before version 4.4, removing a field, or changing a field’s type from non-nullable to nullable would be an outright bad idea. In Corda 4.4 it’s possible to do the latter, and the former is much more predictable. In version 4.6 things around removing fields got better still as you will see later in the blog.
Laying out the basics
It’s important to realise a few things about Corda in order to better understand why things work the way they work.
In Corda, transactions are verified, not states
This may seem obvious but forgetting that even for a minute will create a lot of confusion. In Corda, every transaction has its context in which it is deserialized and verified. The context will always and forever be the set of jars that were used to construct the transaction back when you called the TransactionBuilder in your flow. And no matter on which node the transaction is deserialized and verified, it will always use that context. If the node was missing some jars of the context, it would download them from the peer first.
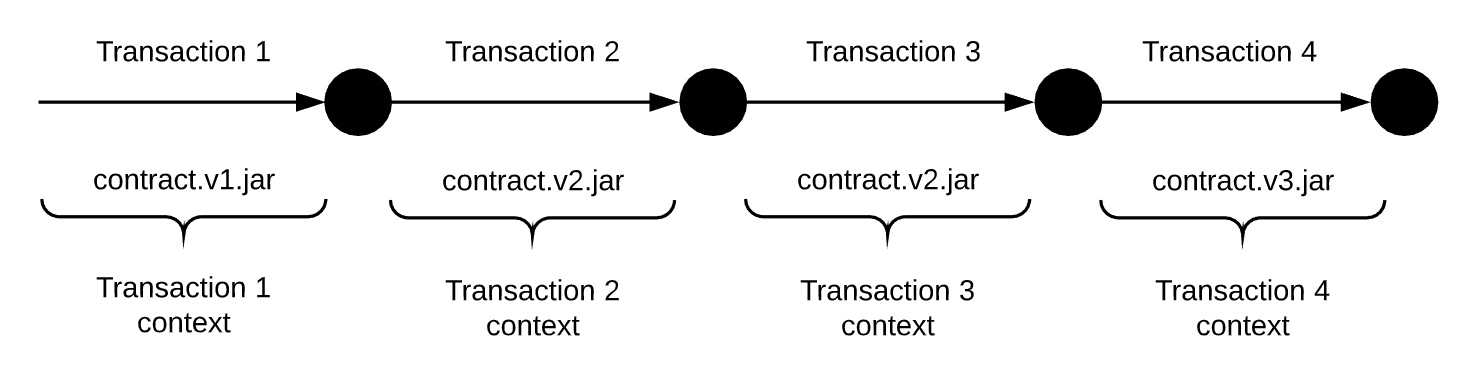
In the above diagram, you can see a simple transaction chain consisting of four transactions. The transactions have been constructed using contract jar versions 1 to 3. The hash of the contract jar used to build the transaction via TransactionBuilder is part of the signed transaction, and Corda will never use any other jar to deserialize and verify it.
You can be asking yourself where all those contract jars are stored. Surely, if you look in the CorDapps directory, you will only find the latest one there. In our example that would be contract.v3.jar. The only other option is that the contract jars are also stored in the database. And that is exactly what happens, they are stored in the db, available to be grabbed via the Attachment Store.
Blobs representing transactions and states on the ledger will never change
The blobs in the Vault will never change, but we can change the way we interpret them.
The defining feature of the Corda ledger is its immutability. In other words, the signed transactions and the states produced by those transactions can never change. The blob in the database representing a transaction and its output states will always stay the same. The closest we can get to editing it is to provide an altered version of the state class used at the time of the creation of the transaction and telling Corda how to deserialize the state from the blob into the new version. Therefore, whilst we cannot change the blob itself, we can interpret it at runtime differently depending on what class we are deserializing it into. Needless to say, there are some very strict rules about what’s allowed and what’s not. More about that further down.
Corda’s deserialization engine can operate in “No-Data-Loss” mode
When this mode is switched on, the deserializer will refuse to parse a blob into a JVM object if that meant any data present in the blob would not get parsed into the JVM object. In other words, if the blob had a state with field X and the field had data in it, and we told the deserializer to parse that blob into a class that didn’t account for field X, then the deserializer would throw an error. If the field X in the blob had null in it, then that would be fine because no data would be lost! I will let that sink in…
Now here’s why this is important to know. When Corda invokes the deserializer in order to build or verify a transaction, it sets the No-Data-Loss mode *on*. When Corda invokes the deserializer for any other reason (e.g. reading states from the vault via Vault Query or receiving a state via Session.receive), the No-Data-Loss mode is *off*.
Armed with this knowledge, everything about upgrading CorDapps should make perfect sense. Let’s divide the upgrade into three parts: updating logic, updating data structures, and updating data.
Updating logic
By updating logic, I mean making changes to one of these parts of the CorDapp:
- Contracts
- Commands
- Flows
- Services
Rolling out an upgrade to contracts and commands only gets complicated if you are not using signature constraints. In which case please refer to this blog on that very topic: Contract Upgrades and Constraints in Corda.
No matter how you end up upgrading the contract jar on the node, if you recall the diagram earlier it should be clear that no change in the contract code affects already existing transactions. They will keep being verified in the context they were built in.
When it comes to flows and services, there are only two things to watch out for here:
- Make sure you drain your node before you upgrade the CorDapp on the node. This could be the point where you start cursing those fabled “long running flows”. So hopefully you don’t have any. More here.
- Make sure that if you are making changes to the protocol of the flow then you either upgrade all nodes at the same time to the new version, or you utilise flow versioning to keep the flows backwards compatible.
Updating data structures
This will be slightly longer so bear with me. By updating data structures, I mean making changes to one of these parts of a CorDapp:
- State classes
- Custom tables for state data (this stuff here)
There must be plenty you want to ask at this stage. So, over to you.
How do I add a field to a state class?
This is actually quite straightforward as you simply need to edit the class. So, say, your class originally looked like this:
data class ExampleState(
val x: String,
override val participants: List<AbstractParty> = listOf()
) : ContractState
And you now need to add two new fields, y and z. One is a non-nullable integer and the other is a nullable integer. Then go ahead and add them.
data class ExampleState(
val x: String,
val y : Int,
val z : Int?,
override val participants: List<AbstractParty> = listOf()
) : ContractState
And you are almost done. Except if you compile this and deploy on your node, you run into obvious trouble. As soon as you try to read from the vault an old state of type ExampleState created with the previous version, the deserializer will throw an error saying it has no clue what to put into the y field. The z field is easy: no z field in the blob means null in the z field in the JVM object and the z field is nullable so no questions there. But we need to help the deserializer with the y field a little. And we can do this by providing a special constructor annotated with the @DeprecatedConstructorForDeserialization annotation. The code should hence look like this. Notice we decided to use 0 as the default value for y but it could, of course, be anything.
data class ExampleState(
val x: String,
val y : Int,
val z : Int?,
override val participants: List<AbstractParty> = listOf()
) : ContractState {
@DeprecatedConstructorForDeserialization(1)
constructor(x: String, participants: List<AbstractParty>) : this(x, 0, null, participants)
}
The deserializer will use this deprecated constructor to create the JVM object representing the state whenever it encounters a blob with only the x and participants fields in it. If you were only adding nullable fields, then you wouldn’t need the special constructor. But you can still put it in your code and if you do, it will get called.
Unless you are upgrading all your nodes at the same time, you may run into a difficult situation when adding new fields. Consider nodes A and B. Node A is running the new version of the CorDapp with a new field in a state class. Node A creates a transaction and makes B a participant on the state. So B will store the state in its vault. But B is running the older version of the CorDapp where the state class doesn’t have the new field. What does that imply? It implies that B won’t be able to create a transaction in which the state is spent. That’s because it would violate the No-Data-Loss rule discussed earlier. Node B will have to upgrade to the new CorDapp version before they can spend the state.
How do I remove a field from a state class?
First of all, if you are running on a version older than Corda 4.4, the only option I can recommend is to deprecate the field. Do not try to remove it.
But even on Corda 4.4 and newer, removing a field is a funny thing. It may feel reasonably straightforward at the beginning when that’s the first and sole change you are making to the state class. But it will quickly explode in complexity with any subsequent changes and the way it works in conjunction with the Deprecated Constructors for Deserialization is not always very intuitive. Further still, before Corda 4.6, the removed field was invisible even to those deprecated constructors, which, I’m pretty sure, is not what you would expect.
For those reasons, my advice is to try not to remove any fields. If you can make the field deprecated, or just learn to live with it, you will save yourself from a lot of thinking about the compatibility between the possible shapes of the state in the blob and the state class in your code, and you will avoid navigating around Corda’s deserializer’s expectations. But if you are brave or have a very strong reason to get rid of that field then read ahead.
First, a reminder about the No-Data-Loss rule, because it has implications here. If you decide to ignore the No-Data-Loss rule, take out a field from your state class, and deploy, then you won’t be able to spend any existing state that has a non-null value in the field. If you did try to create a transaction spending such state, the No-Data-Loss rule would kick in and not let you do that.
Is there anything else to consider? Plenty. I was going to treat you to a very long passage of text here explaining what to do in which situation but then I realised that one image can really be worth 1,000 words. So, imagine you have a state class with a field X in it and you don’t want that field any more… Now, please follow me and let me ask you a few questions… And remember, I assume you are running at least Corda 4.4!
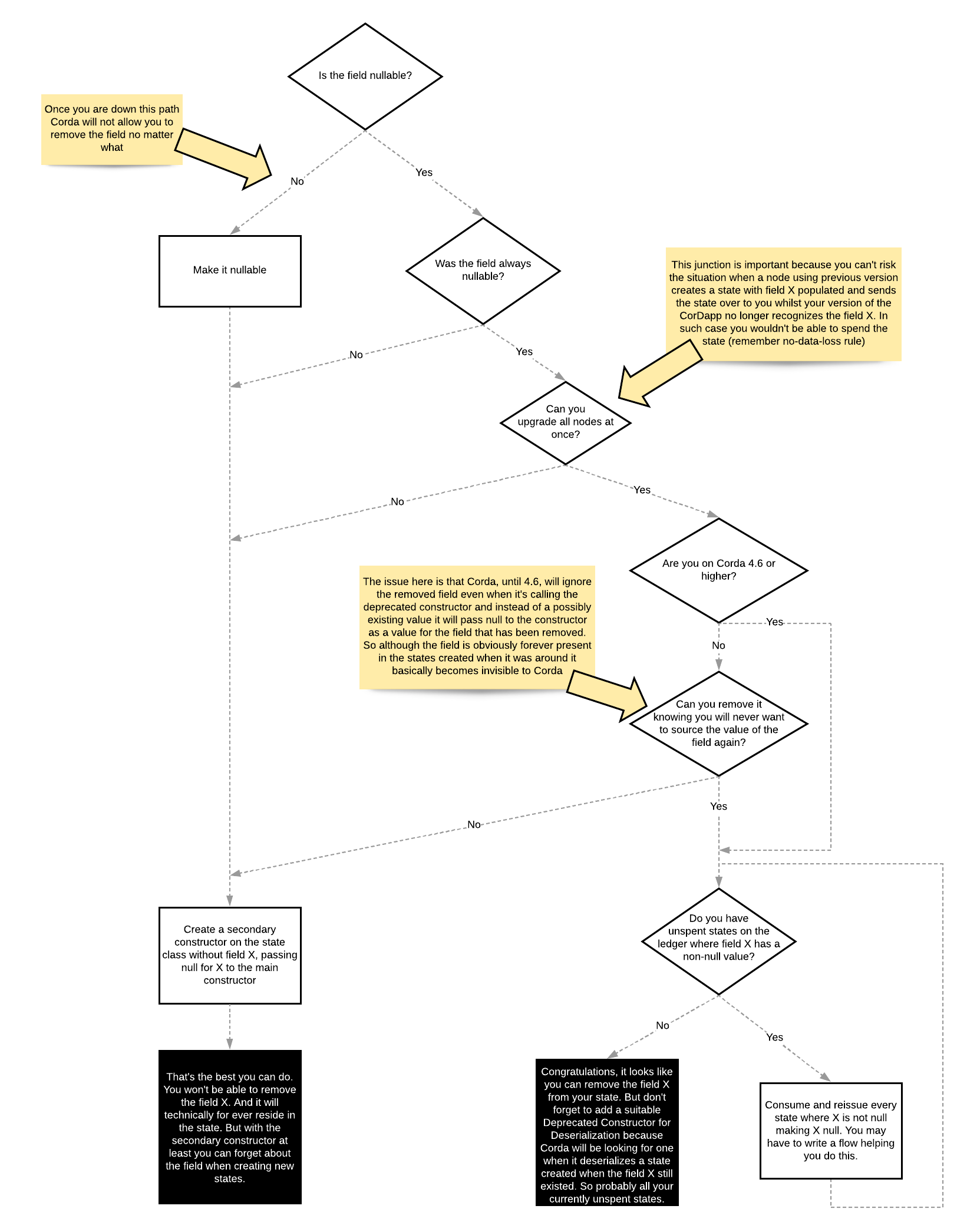
As you can see, only in a very specific situation you can go ahead and remove the field from the class. In that situation, you keep the Corda deserialization mechanism from breaking, you don’t risk being stuck with an unspendable state, and if you are running an older version than 4.6 you also know that you will never want to look at that field again. In all other situations, the best you can do is to deprecate the usage of the field whilst keeping it in the class.
How do I change the type of a field in a state class?
Since Corda 4.4, changing type from non-nullable to nullable is supported. So you can simply change, for example, Int to Int? or String to String? and get away with it.
Other than that, changing the type of a field (let’s call it again field X) is not straightforward. The short answer would be that it’s not supported. You can work around it by introducing a new field (let’s call it field Y) with the desired type, using the constructor annotated with @DeprecatedConstructorForDeserialization to populate the new field Y from the old field X, and then deprecating the use of field X and potentially removing it.
Please note that changing a field from nullable to non-nullable also counts as changing the type of the field. If you are changing from nullable to non-nullable, you will of course need to think of a default value to use when the original field value is null.
How do I change the name of a field in a state class?
Same story as for changing the type of a field. Not directly supported. You can again work around it in the same way — add a new field with the name you are after, let it take on the value of the old field with the old name in the constructor for deserialization, deprecate the use of the old field and eventually, maybe, remove the old field.
Can I split a state in two or merge two states into one?
Unsurprisingly there’s nothing to use out-of-the-box. And it wouldn’t really make sense.
Splitting a state into two will require writing the two new state classes, using transactions to consume the states of the old type, and issuing two new states of the new types. If you wanted to keep the name of the old state (i.e. splitting state X into altered state X and new state Y), then that would be same as creating one new state type (Y) and setting fields in the old state (X) to null (via a transaction) as the values migrate to the new state (Y, in the same transaction). Later, when the migrated fields in state X have null values, you can consider removing those fields from the state class X.
Similarly, merging two states into one means a new state should be defined and the data in the two separate states have to be migrated to the new state via a transaction consuming the two old states and creating one new state with the same data on the ledger. If you wanted to keep one of the two state’s name (i.e. merging X and Y into an altered state X), then that would be equal to adding Y’s fields to X state class, consuming states X and Y via a transaction, and producing state X with Y’s values in it on top of its original fields and values.
Bear in mind that changing the meaning of a state whilst keeping its name is in most cases a first-class ticket to a confusion-fair.
And what about the custom tables for state data?
In other words, what about the PersistentState classes annotated with @Entity that will take care of storing the state data into the db in your chosen shape and format?
You don’t have to worry about the type or data evolution too much here. Corda will never deserialize from a row in the custom table into a JVM object and hand it over to you as a Corda state. So you just need to make sure about these two things:
- The PersistentState class matches the underlying db table.
In Corda Enterprise you would write a Liquibase script performing the necessary alteration of the table. In Open Source you would alter the table manually before you start the node with the updated CorDapp. If you are adding a field and it has a default value then don’t forget to back populate the existing rows with that default value. - The PersistentState class must have a default no-arg constructor.
This is because when you use the class to execute a query on the vault, the class will get temporarily instantiated by Hibernate. And it needs to know how to instantiate it.
Updating Data
Updating data may seem odd. After all, it’s an immutable ledger. Things are supposed to evolve based on smart contracts and consensus among participants strictly in some business context. At least that’s how a lot of us have been trained (perhaps unintentionally) to think. But there’s nothing wrong with evolving data for reasons outside the intended use cases. E.g. because we are doing an upgrade or because someone realised that we should have been recording amounts in pennies rather than pounds.
What we will have to do in such a situation, however, is write a dedicated flow that we can deploy, trigger, and then let it take care of updating the data by consuming states and reissuing them with the new content. The flow will of course have to obey the contract rules and seek agreement from other participants, just like any other flow. It will pay off to think carefully about which of the, potentially, multiple participants should trigger the process so that we don’t unnecessarily update the same state multiple times (which in the case of changing amounts from pounds to pennies could have consequences!), and we don’t run into double-spend errors on the Notary.
Generally, this process is quite similar to deleting and reinserting a row in a traditional database within the same database transaction. But of course, here we seek consensus first before we do that, and we are constrained by what the smart contracts allow.
Summary
With signature constraints, upgrading the logic of your CorDapp really became much simpler. When it comes to data structures, there is support for adding fields, but please remove fields only if you absolutely have to and know exactly what you are doing. Oftentimes, deprecating the field or an entire constructor may be as good as removing, but without the pain. The other operations will have to be some combination of adding and deprecating/removing. In respect to data updates, we really shouldn’t feel like that’s a no-go zone on DLT. Instead, a data update performed as part of an upgrade or for other technical reasons is a very valid use of the DLT.
Disclaimer
Whilst I spent hours going through possible upgrade scenarios it’s possible that my recommendations and observations will not work in your case. So test thoroughly before you do any upgrade in production.
Want to learn more about building awesome blockchain applications on Corda? Be sure to visit https://corda.net, check out our community page to learn how to connect with other Corda developers, and sign up for one of our newsletters for the latest updates.